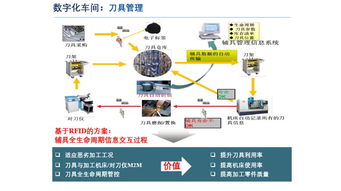
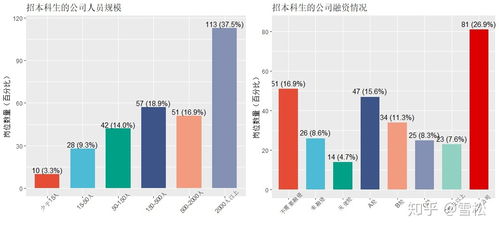
隨著人工智能技術的飛速發展,人工智能基礎軟件已成為驅動產業升級與創新的核心引擎。從深度學習框架到模型部署平臺,從數據管理工具到自動化運維系統,這一領域的軟件開發與項目管理正面臨著前所未有的機遇與挑戰。傳統的軟件工程方法論在應對AI項目的特殊性時,亟需進行適應性調整與創新融合。
一、人工智能基礎軟件開發的獨特挑戰
人工智能基礎軟件的開發與傳統業務軟件存在顯著差異,其核心挑戰主要體現在以下幾個方面:
- 高度不確定性:AI模型的性能與效果往往難以在開發初期精確預測,依賴于數據質量、算法選擇及超參數調優,這使得需求范圍、進度評估和成果驗收的標準變得模糊且動態。
- 數據驅動的核心地位:項目的成敗極大程度上依賴于數據的獲取、清洗、標注與管理流程。數據工程與算法工程緊密耦合,數據管線的穩定性和可擴展性成為系統架構的關鍵。
- 研究探索與工程交付的平衡:項目常包含探索性研發階段,需要允許試錯和迭代。如何將研究成果穩定、高效地轉化為可復現、可維護、高性能的生產級代碼,是工程化的核心難題。
- 技術棧快速演進與生態依賴:框架(如TensorFlow、PyTorch)、硬件(如GPU、NPU)及各類工具鏈更新頻繁,項目在技術選型上需兼顧前沿性、穩定性與團隊能力,并管理復雜的依賴關系。
- 對算力資源的強依賴:模型訓練與推理需要巨大的計算資源,成本高昂。資源調度、成本控制與性能優化貫穿項目始終。
二、適應AI特性的開發項目管理策略
為應對上述挑戰,軟件工程項目管理需要在經典實踐基礎上進行迭代與創新。
- 敏捷與迭代的深度融合:采用高度靈活的敏捷或Scrum框架,但周期和目標設定需適應AI研發節奏。明確區分“探索沖刺”(專注于算法實驗和驗證)與“交付沖刺”(專注于工程化、集成與測試),并建立相應的成果評估標準(如模型指標、代碼質量、文檔完整性)。
- 數據與模型的全生命周期管理:將數據管理與模型管理提升至與代碼管理同等重要的地位。建立版本化的數據集倉庫和模型倉庫,追蹤數據血緣和模型譜系,確保實驗的可復現性。實施MLOps(機器學習運維)實踐,自動化模型的訓練、評估、部署、監控與迭代流程。
- 跨職能團隊與角色演進:組建融合數據科學家、算法工程師、軟件工程師、數據工程師、運維工程師及領域專家的跨職能團隊。明確角色職責,促進緊密協作。特別是需要強化“AI軟件工程師”的角色,他們擅長將算法原型轉化為魯棒的、可擴展的軟件系統。
- 風險前置與持續驗證:將技術驗證(Proof of Concept, PoC)和可行性研究作為關鍵的前置階段。持續進行模型性能評估、系統集成測試和A/B測試,將驗證反饋快速融入開發循環。建立完善的監控體系,對線上模型的性能衰減、數據漂移等問題進行實時告警。
- 技術債與知識管理:由于前期探索的代碼可能較為粗糙,必須有計劃地重構和償還技術債。加強文檔化工作,不僅記錄代碼邏輯,更要記錄實驗設計、參數選擇依據和決策過程,形成團隊可共享的知識庫。
- 工具鏈與平臺化建設:投資建設或引入統一的AI開發平臺,集成數據管理、模型開發、實驗跟蹤、資源調度、部署服務和監控等功能。通過平臺化降低協作成本,提升開發效率,并保障最佳實踐的落地。
三、未來展望
人工智能基礎軟件的開發將更加趨向于自動化、標準化和規模化。低代碼/無代碼的AI開發工具、自動化機器學習(AutoML)技術將進一步降低應用門檻,但核心框架、高性能運行時和系統級軟件的開發將更加注重極致性能、安全可信與跨平臺適配。項目管理的重點也將從單一項目的交付,轉向構建可持續演進、安全合規、能夠創造持續業務價值的AI資產與能力平臺。
在人工智能基礎軟件的浪潮中,成功的項目管理不再是簡單的進度、成本與范圍的控制,而是演變為一種對不確定性、技術復雜性和創新節奏的深度管理能力。它要求管理者兼具技術洞察力、流程設計能力和生態視野,帶領團隊在探索與交付、靈活與規范、創新與穩定之間找到最佳平衡點,最終交付可靠、高效且具有長期生命力的智能軟件系統。